CS 4641 Spring 2020 Team 22
Team members: Shaohua Shen, Zhou Lu, Jianing Fu, Sizhe Liu
Motivation of Project
Throughout the past decade, video consumption has steadily shifted from traditional cable to online streaming platforms. Services like Netflix, Hulu, and HBO NOW are growing faster than anyone can expect. Even traditional tech companies like Amazon and Apple are trying to step into the tv industry by producing their own shows on their platforms like Amazon Prime Video and Apple TV+. Predictions state that the global online video streaming market size will reach USD 184.3 billion by 2027[1], and the key to success and gaining more subscriptions is to produce and stream good quality TV shows/moives. There is an increasing amount of interest in predicting a show’s quality on social media, but not a lot of research has been conducted using machine learning. Therefore, we deem it worthwhile to see how machine learning techniques, such as neural networks, can lead to better prediction for quality shows/movies.
Dataset and Pre-Processing
Our source is from the IMDb Dataset[2] and the OMDb API[3]. We first pulled a list of every IMDb entry with their basic information including formats, title, releasing dates, length, etc. Within nearly 10 million entries, we filtered out all the entries that has less than 5000 counts of ratings since fewer number of rating might be bias so that cannot be a good measurement. We also filter out entires produced before year 2000 since the audience’s taste would change with time. Detailed information of the filtered dataset was pulled from the OMDb API, giving 10,489 entries.
Dataset Features
There are 24 features in the dataset:
- “title”, title of the movie
- “year”, production year of the entry
- “rated”, parental guidance rating of the entry
- “released”, excat release date of the entry
- “runtime”, totalu runtime in minutes of the entry
- “genre”, genre of the entry
- “director”, director of the entry
- “writer”, writer of the entry
- “actors”, actors of the entry
- “awards”, awards won by the entry
- “ratings”, rating of the movie by other platforms
- “metascore”, rating by metacritic
- “imdb_rating”, rating by imdb users
- “imdb_votes”, number of the votes
- “imdb_id”, imdb id for the entryent
- “type”, type of the entry (movie/shows)
- “dvd”, release date of the DVD
- “box_office”, box office of the entry
- “production”, production company of the entry
- “website”, website of the entry
- “plot”, plot of the entry
- “poster”, link to the poster of the entry
- “language”, language of the entry
- “country”, country the entry was produced in
This project is trying to predict the entry’s “imdb_rating” by other given information.
Data Pre-Processing
Irrelevent Features
“Plot”, “Poster”, “Language”, and “Country” was deleted from the dataset since it’s hard to analysis or might be discriminative. Features that are irrelvant to the analysis were also dropped including title, imdb_id, imdb_votes, box_office, website, release date, dvd. ratings, metascore, and awards were dropped since the movies/shows that we are trying to predict would not have these information before they were aired.
Feature Quantization
We quatized features including “rated”, “actors”, “director”, “writer”, “runtime”, “production” by calculating the mean imdb_rating of each category/person’s work and normalized from 0 to 10.0.
Feature Analysis
After quantize the features, we plot and visualized the correlation matrix and covariance matrix to show their relationships:
The labels appears in order of “actors”,”genre”, “director”, “writer”, “production”, “rated”, “runtime”, “imdb_rating”
Correlation matrix:

Covariance matrix:

Dataset Visualization
After filtering movies that have insufficient ratings as well as old movies produced before the year 2000, we ended up with 10489 entries. We quantized the features used for our predicted model using the IMDB rating system, normalized. The following graphs show the number of films within each IMDB rating (fit to histogram buckets) for Actors, Genre, Director, Writer, Production, Rated, and runtime, as well as net IMDB rating.
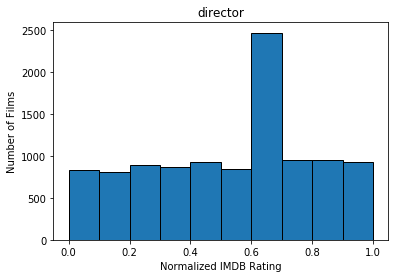
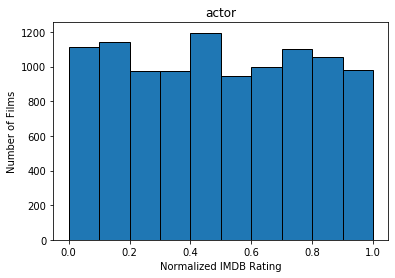
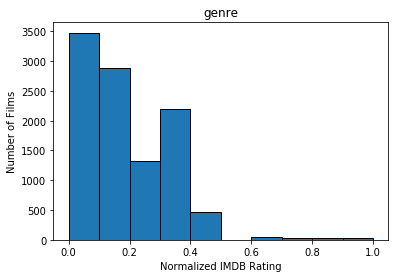
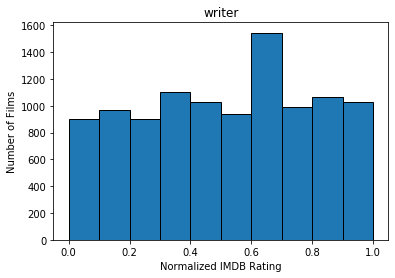
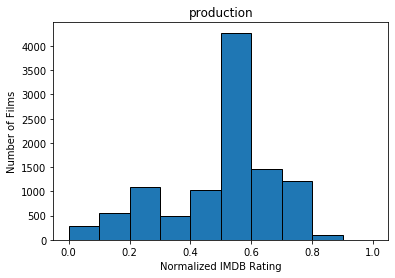
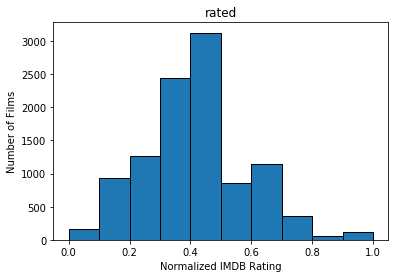
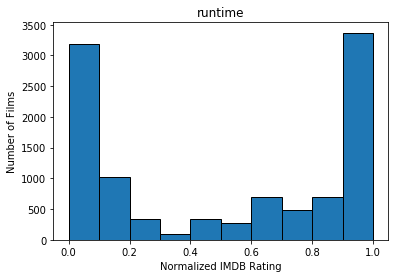
Methods
Regression
Linear Regression
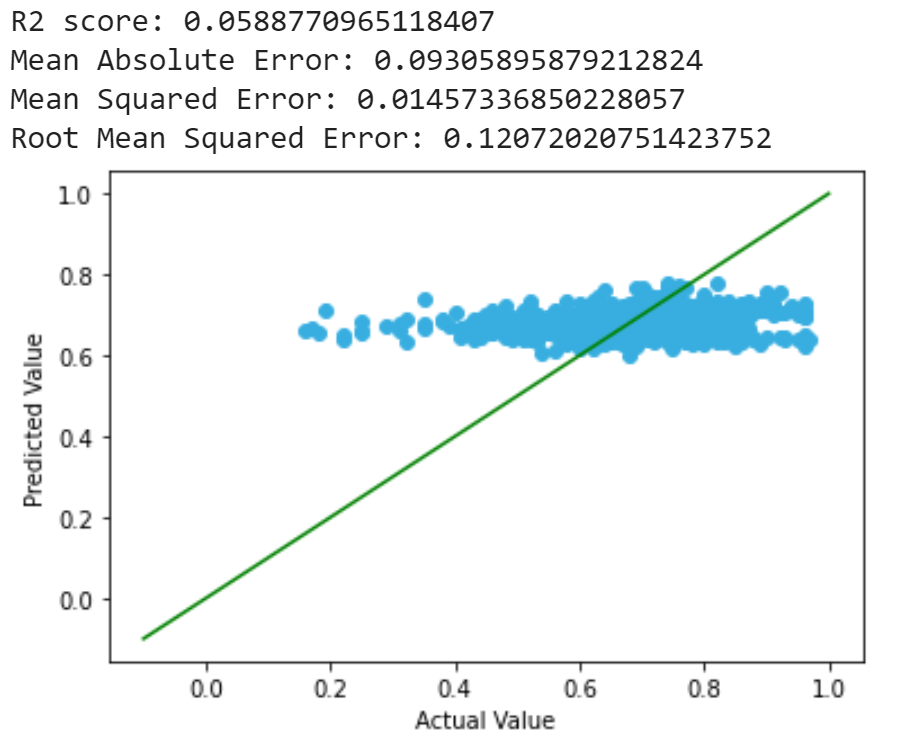
We decided to make our first predictions with linear regression. We used regression tool from scikit-learn library to achieve this. Regression fits the situation well since it’s simple and able to predict continuous values. We first attempted to use simple linear regression, but the results are not ideal, most of the predictions falls in range [0.6, 0.8], while the actual values vary largely, the restult is shown as below:
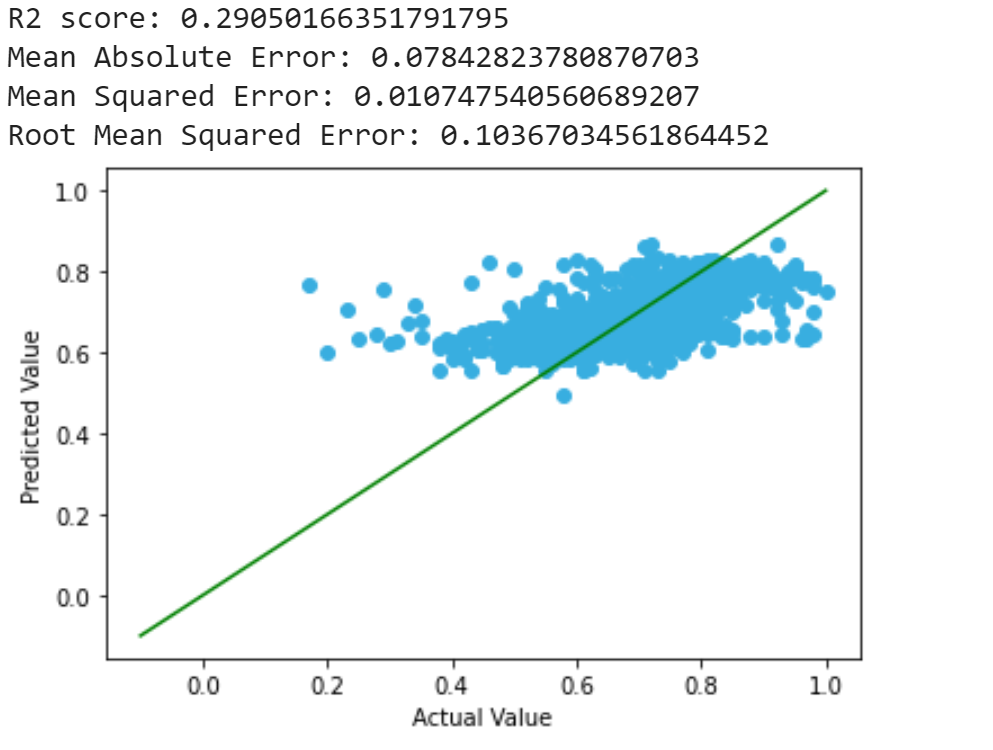
Polynomial Regression
To improve our result, we then applied polynomial regression, to take the interaction between factors into consideration:
Ridge & Lasso
Aside from simple regression we also tried adding regularization factors into the regression model:
Ridge
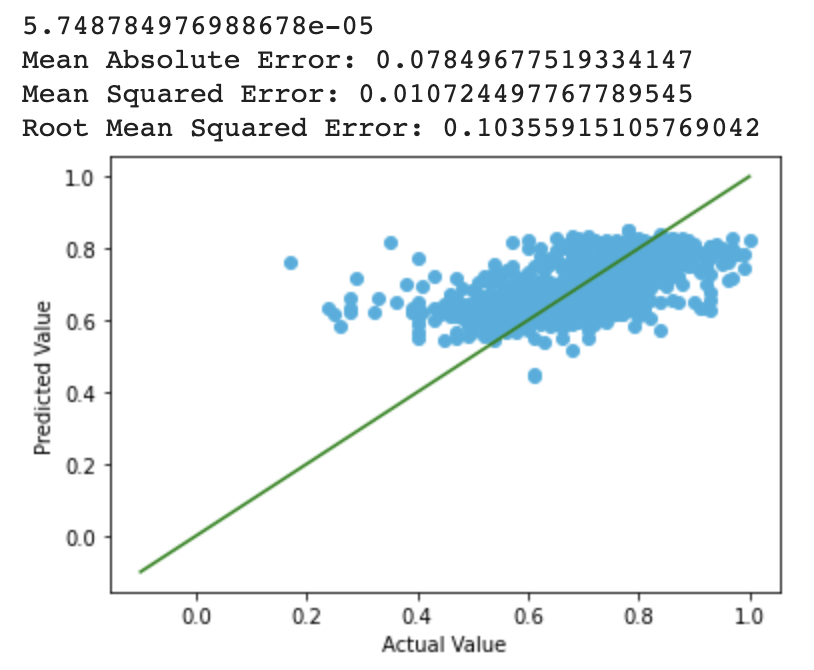
Lasso
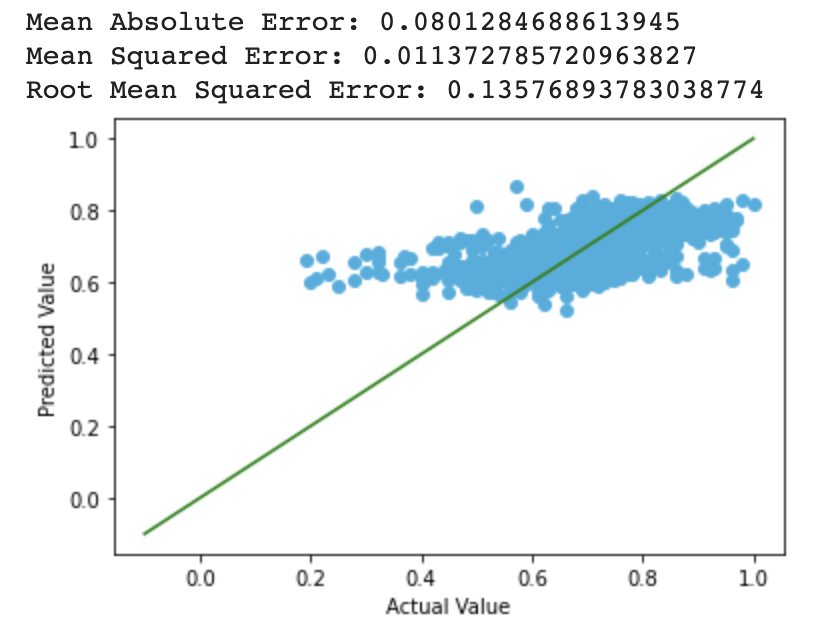
We observed that the range of prediction lies in range [0.4, 0.9] after applying polynomial regression, which is a large improvement, but the results are still not optimal. One possible explanation is that most film ratings fall in the range of [4, 9], and it is unusual for a film to either not recieving any critical comment (>9), or recieving only critical comments (<4), and there might be factors that we did not take into consideration that could still affect the rating of the film.
Neural Network
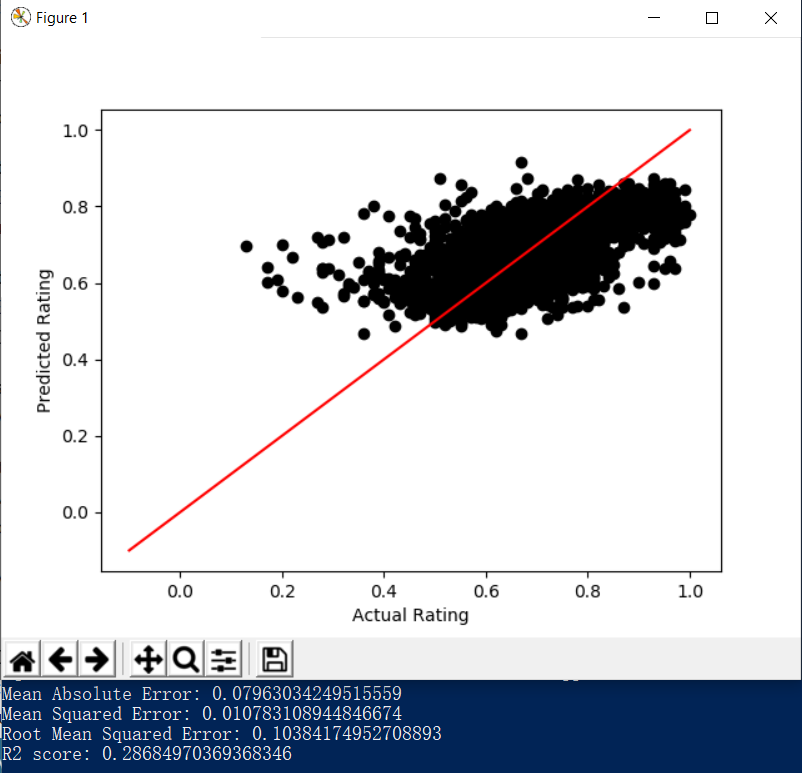
We also used neural network for prediction. Neural network is widely utilized in predictive analyzing problems that are similar with ours. Similar with regression, we used scikit learn tools to implement our nn model. To be more specific, we took use of the MLPRegressor class, which is a multi-layer perceptron regression system. It uses the square error as the loss function, and the output is a set of continuous values. For the parameters employed in our network, the activation function is Relu and optimization solver is Adam. Our learning rate is initially 0.0005 and constant during the time. The results we received from the model are shown below, including errors and R2 score:
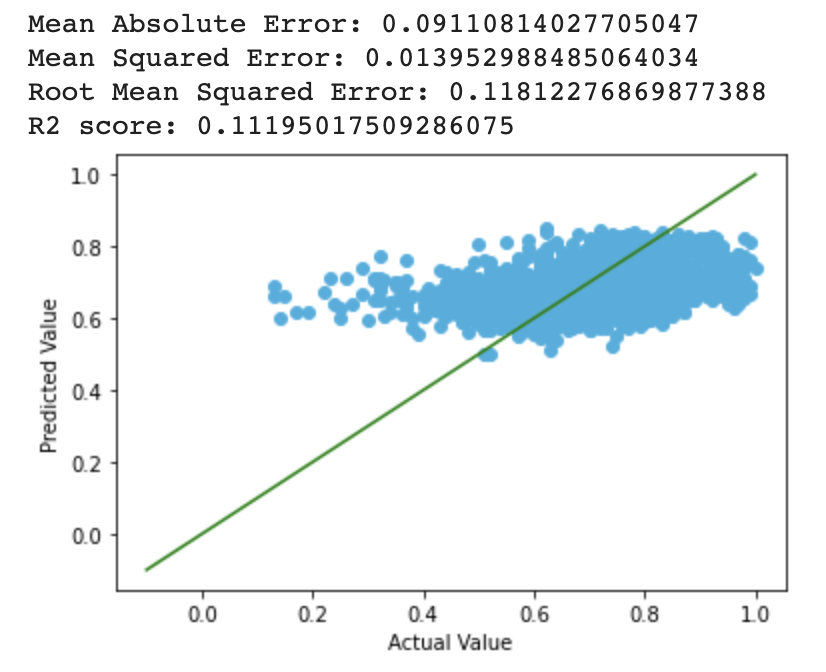
The Root Mean Square Error was 0.118, and the R2 score was 0.112. We tried using different learning rates and optimization solvers. The best result we have in one run so far was below:
Conclusion
Throughout the project, we gathered over 990,000 entries and unsampled unpopluar and old entries which would not provided valid rating information for predicting today’s market behavior. We decided to analysis over 10,000 movies/shows released after year 2000 and with over 5000 votes.
A) Feature Selection
While more complicated datasets demand the use of random forests and other machine learning methods to narrow down their feature sizes, our team opted to utilize old-fashioned common sense to select the number of features, dropping features that we deem to be discriminating or simply difficult to quantize, such as Plot, Language, Nation of Origin, etc, or features that would not be available prior to the premiere of a new movie (and therefore would be pointless to account for). We decided to do this because the data we scraped provided a sufficiently small set of features to train an efficient model without too much worry of overfitting or an excessively long training time. Also, previous data has shown that the features we selected are very accurate in predicting the rsuccess of a film, though not necessarily in popularity.
B) Regression Models and Neural Networks
We experimented with both regression models and neural network models to help predict the expected popularity of the testing data set versus the training data set. We had the expectation that the neurla network would be better able to capture the specifics of the data set, but we discovered that the performance of the Neural Network versus the various regression models (including Linear, Polynomial, Lasso, and Ridge Regression) did not have sufficient differences in RMS error to justify one over the other on a basis of pure accuracy. Ridge and Polynomial regression contained the lowest RMS error for both models, suggesting that it would be the most helpful for our current endeavor, though the numbers are too close to declare either a winner. Using the best learning rate we tested, we found that the neural network yielded results comparable to that of the Ridge regression in both range of predictions and the RMS error of the predictions. Note that our ridge regression also utilized polynomial regression.
C) Results
Predicting the popularity of a movie is a complex problem that is subject to a variety of factors that cannot be easily quantifiable into data values/labels. The results were somewhat promising, with an average error of prediction of our testing data set within 10%. Ridge regression and an optimized Neural Network, our two best results, allowed us to reach average errors within 8%. Therefore, while there is still a significant error to be considered, our model serves to provide theaters with a rough estimate of the potential success of a movie, which can be helpful for allocating the amount of airing spaces on a movie theater, decide the stocks available in a Blockbuster-type movie rental store or to optimize storage caches and latencies on a streaming service web server/content delivery network. The latter is especially important in ensuring a smooth viewing experience for the customers of the streaming company and to protect the infrastructure of the service from being overwhelmed. This is a helpful field to address because traditionally caching strategies cannot preemptively provision storage for popular movies that have yet to be released to viewing. Using our model, a streaming service can preallocate bandwidth and storage for popular movies with reasonable accuracy, massively reducing server load and viewer buffering.
D) Future Work
We believe that our prediction accuracy is hampered by insufficient data, most notably the production and advertising budgets of the film. Judging from the predicted results having a much closer spread (standard deviation) than the actual results, especially for the linear regression case, we can assume that we lack an important feature in our dataset that effectively discriminated the success of an individual movie, and that our model was forced to “guess” these results from the remaining parameters. An example would be a science fiction movie netting a high predicted popularity regardless of inherent quality due to the fact that sci-fi movies tend to be in well-advertised franchises (e.g. Star Wars, Star Trek) and have high special effect budgets. Therefore, we believe that future work should be done with a more expansive movie dataset, which would help provide these crucial parameters to predict popularity upon.
Reference
[1]“Video Streaming Market Worth $184.3 Billion By 2027: CAGR: 20.4%.” Market Research Reports & Consulting, www.grandviewresearch.com/press-release/global-video-streaming-market.
[2] Datasets.imdbws.com, datasets.imdbws.com/.
[3] “OMDb API.” OMDb API - The Open Movie Database, www.omdbapi.com/.